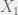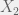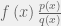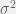January 22, 2012
by colorgas
Why I want to re-understand VSM
In the original VSM paper,William and Andrew derived the MAGIC result from probability theory:

Note: 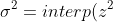-interp(z)^{2} "\sigma ^{2}= interp(z^{2})-interp(z)^{2}")
Note: 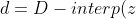 "d = D - interp(z)")
 means the shadow map depth or shadow caster depth in shadow map
means the shadow map depth or shadow caster depth in shadow map "interp(z^2)") means the interpolated( filtered)
means the interpolated( filtered)  value in shadow map
value in shadow map "interp(z)") means the interpolated(filtered) value in shadow map
means the interpolated(filtered) value in shadow map- D means the shadow receiver’s depth)
The derivation looks very beautiful, but not so easy to understand , especially the idea to treat z as a random variable, so here I’ll try to explain it by middle school math, then we can kill the uncomfortable MAGIC feeling.
Analysis
Firstly, let’s back to the problem why VSM had been invented : Soft Shadow.
In the real word,soft shadow are generated with a physic explanation(eg area light),
but visually, Soft shadow just means a smooth transition between shadowed area and unshadowed area.
so there are many methods to fake it in computer graphics, VSM is just one of them ( note: even with beautiful math, VSM is not a physic correct algorithm at all).

In the above graph, we have 2 neighborhood texels in shadow map corresponding to 2 light rays, their shadow depth value are Z1 and Z2,.
According shadow map algorithm, we can know pixel A is in shadow and pixel B is lit, what we care about is the area between A and B,
If applying regular shadow test, a sudden shadow density changing must happen at somewhere between A and B. Even we can use bilinear filter to fetch shadow, the smooth input value doesn’t generate a smooth output value because shadow testing result is a binary value. That is why we said shadow map is not filterable.
Let’s see what will happen if we apply the MAGIC shadow testing formula from VSM.
First, let’s introduce a interpolating variable t, t will be changing linearly (0-1) from pixel A to pixel B.
Then with linear filtering, between A and B, we can write:
= Z_{1}^{2}\times (t-1) + Z_{2}^{2} \times t "interp(z^2)= Z_{1}^{2}\times (t-1) + Z_{2}^{2} \times t")
= Z_{1}\times (t-1) + Z_{2} \times t "interp(z)= Z_{1}\times (t-1) + Z_{2} \times t")
Then
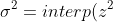-interp(z)^2 = (Z_{2}-Z_{1})^{2} \times (t^{2}-t) "\sigma ^{2}= interp(z^{2})-interp(z)^2 = (Z_{2}-Z_{1})^{2} \times (t^{2}-t)")
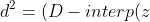)^{2} "d^2 = (D-interp(z))^{2}")
So
^{2}}{t-t^{2}}} "PShadow = \frac{\sigma^{2}}{\sigma^{2}+d^2} = \frac{1}{1+\frac{d^2}{\sigma^{2}}} = \frac{1}{1+\frac{(slop -t)^{2}}{t-t^{2}}}")
here, we define:

Looks still mess, right?
Let’s see 2 special cases :
Special case 1: Perpendicular Reciever:
when receiver surface perpendicular to light direction (see reciever Rp)

For this scenario , we can easily know  ( between t=0 and t=1)
( between t=0 and t=1)
So 
Then final result:
^2}{t-t^2}}=t "PShadow_{perpendicular} = \frac{1}{1+\frac{(1-t)^2}{t-t^2}}=t")
So for this case, the shadow result will follow the most simple smooth transition when t change from 0 to 1 : Linear transition.
Special case 2: Reciever on interp(z):
When Shadow Reciever are on interp(z) ( see the red dash line in above picture).
According
we can know immediately:

Combine the two special cases,and the property of that Pshadow is a Monotonic function decreasing function to D (see Appendix)
For the area between interp(z) (red dash line) and Reciever Rp, we have:

we can say: PShadow is Monotonic changing between t and 1 along D decreasing. it’s a smooth transition too.
For the portion below Rp, the situation is same but the PShadow < t.
Short Summary
- with t increasing to 1, PShadow will increase to 1 smoothly
- with D decreasing to interp(z), PShadow will increasing to 1 smoothly too.
- when ( receiver surfaceperpendicular to light) , it’s a linear transition.
Conclusion
From the result, we can say ShadowMap filtering start to make sense, since a interpolated shadow depth can generate a shadow value between 0 and 1. that’s why we say VSM is filterable.
we can go one step forward, if we blur the shadow map texture, the same transition effect will expand from 2 neighborhood shadow depth texels to more adjacent texel, then it results a more smooth shadow transition, that’s why we say VSM is pre-filtable.
Appendix:Pshadow is a Monotonic decreasing funtion to D.
Check the original define:
since if t is fixed,
is a fixed value,
so if D is increasing, then d is increasing, then Pshadow is decreasing,
Then we can know Pshadow is a Monotonic decreasing function to D.
PS. the original VSM paper can be downloaded at :
VSM “Variance” http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.104.2569&rep=rep1&type=pdf